41 KiB
+++ title = "Porque Você Deve Aprender Rust" date = 2019-09-25
[taxonomies] tags = ["rust", "companion post"] +++
Rust é uma nova linguagem de programação que eu acredito que deveria ser vista por desenvolvedores, mesmo que eles não venham programar em Rust.
{% note() %} Esse post acompanha a minha apresentação Porque Você Deve Aprender Rust. {% end %}
Quando eu comecei a apresentação, eu pensei em chamar a mesma de "Porque Você Deveria Aprender Rust"; mas eu pensei bem sobre isso e como a linguagem tem vários conceitos interessantes, eu acho que o título correto deve ser "Porque Você DEVE Aprender Rust".
Mas antes de começar a falar sobre Rust, é interessante que vocês conheçam quem está dizendo que vocês "devem aprender Rust":
Eu comecei a programar a mais de 30 anos. Em todos esses anos, eu já programei em Basic (usando número de linhas e Basic estruturado, também conhecido como QBasic), dBase III Plus, Clipper (que foi a primeira linguagem que eu usei profissionalmente), Pascal, Cobol (sim, Cobol, façam suas brincadeiras agora), Delphi (cujo nome científico é "ObjectPascal" e possui algumas diferenças para o Pascal original), C, C++, ActionScript (que é a linguagem para geração de applets Flash sem usar o editor da Adobe), PHP (quem nunca?), JavaScript (quem nunca?), Python, Objective-C, Clojure, Java, Scala (que eu não desejo que nem meu pior inimigo tenha que programar nela) e Rust. E essas são as linguagens que eu já escrevi código e que rodou. Fora essas, eu ainda conheço Haskell, Perl, um pouco de Ruby e Swift, mas nessas eu não programei nada ainda.
Mas por que eu comentei sobre isso? Porque o que eu vou comentar aqui é, basicamente, minha opinião, depois de conhecer essas linguagens todas. Então, obviamente, existe um viés para os motivos que eu vou citar daqui pra frente.
Mas existe uma frase do Alan Perlis, criador do ALGOL, que diz "A language that doesn't affect the way you think about programming, is not worth knowing" (uma linguagem que não afeta o modo que você pensa sobre programação, não vale a pena ser aprendida). E mesmo depois de todas essas linguagens citadas acima, Rust ainda me fez repensar coisas que eu sempre pensei quando estava programando.
A Parte Burocrática
Antes de sair falando da linguagem, eu tenho que falar sobre a parte burocrática da linguagem. Coisas como, por exemplo:
- Rust foi criada em 2006 por Graydon Hoare.
- Rust começou a ser patrocinada em 2009 pela Mozilla Foundation.
- A versão 1.0 saiu em 2015.
- A versão atual é a 1.37.
Rust tem uma história engraçada: Hoare começou a desenvolver a linguagem de forma independente, em seu tempo livre. Quando ele começou a pegar gosto pela coisa, ele veio falar com seu gerente dizendo que iria deixar a Mozilla Foundation para poder trabalhar na sua linguagem de programação. "Que linguagem é essa?", perguntou o gerente; Hoare afirmou que era uma linguagem com foco em proteção de memória mas que ainda fosse uma linguagem rápida. Ao ouvir isso, o gerente pediu para Hoare segurar o pedido de demissão e conversou com seus superiores. E, por ter vários problemas com a estrutura em C++ do Firefox, a Mozilla resolveu patrocinar Hoare para que ele pudesse trabalhar na linguagem.
{% note() %} Eu gosto de brincar, dizendo que o Hoare chegou pro gerente dele dizendo que iria deixar a Mozilla pra trabalhar na sua linguagem e o gerente, depois de pedir pra ele esperar um pouco, chegou dizendo que só conseguiu 2 estagiários.
A verdade é que Hoare realmente quis deixar a Mozilla Foundation, mas ao explicar os motivos -- trabalhar na sua própria linguagem, cuja principal diferença seria a proteção de memória e velocidade -- a Mozilla se interessou pela mesma, por causa dos problemas que eles estavam encontrando ao trabalhar com C++. Por isso a Mozilla continuou pagando Hoare para que ele trabalhasse na sua linguagem. {% end %}
Uma coisa a cuidar: Aqui eu comento que a versão atual é a 1.37. Isso pode não ser verdade no momento que você lê esse post (ou viu a apresentação) porque a cada 6 semanas uma nova versão do Rust é liberada. Essas versões trazem correções de bugs e novas features.
{% note() %} Uma outra anedota é que o primeiro projeto em Rust foi um browser -- normalmente a gente pensa que para primeiro projeto, as linguagens querem algo mais simples, como um microserviço ou algo parecido, mas a equipe do Rust partiu direto para um browser.
O resultado, chamado Servo, hoje faz parte do Firefox Quantum, o que diminui o uso de memória e diminuiu o número de "crashes" da aplicação.
Ainda, num certo ponto, um desenvolvedor do Chrome resolveu fazer alguns testes, utilizando SVG animados, colocando 1 elemento animado 300 vezes numa página. Para animar todos os elementos, o Chrome conseguia manter 30 FPS; Firefox, 20; Servo, 300 (sim, 10 vezes mais que o Chrome!).
Outro exemplo de Rust no Firefox é um bug que estava em aberto por 8 anos. O bug em questão, 631527 -- que, na verdade, é uma feature -- seria permitir que dois elementos possam ter os estilos definidos no CSS aplicados em mais de um elemento ao mesmo tempo; o browser lê primeiro o HTML, constrói o DOM e depois sai aplicando o estilo em cada um dos elementos; com dois elementos um depois do outro, seria, teoricamente, possível aplicar o estilo no primeiro ao mesmo tempo em que aplica no segundo. O bug ficou aberto por 8 anos e duas re-escritas foram feitas pra tentar resolver o problema. Nenhuma conseguiu prover um resultado funcional, por vários motivos, mas principalmente por causa da forma com a memória era compartilhada nas threads em C++. Quando o Firefox mudou para o Quantum (de novo, em Rust, usando a base do Servo), a correção foi (conforme descrito por Niko Matsakis na abertura do Rust Latam 2019) "trivial". {% end %}
Motivo 1: Quem Usa, Gosta
Em 2019, O StackOverflow fez uma enquete com os visitantes, perguntando, entre várias outras perguntas, qual linguagem eles usavam e se eles gostavam de programar nessa linguagem. No resultado dessa enquente, Rust aparece como a linguagem mais amada... pelo 4o ano seguido.
"Ah, mais isso é fácil! Os quatro caras que programam em Rust dizem que gostam dela todo ano!", você deve estar dizendo. Na verdade, o percentual tem subido desde a primeira vez, saindo de 76% em 2016 e indo a 83% em 2019.
Motivo 2: "Uma Linguagem de Baixo Nível Com Abstrações de Alto Nível"
Quando comparado com C, Rust tem uma performance bem semelhante:
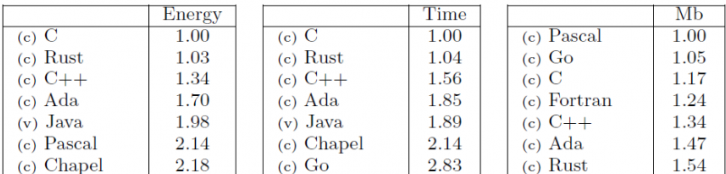
O gráfico acima foi tirado de uma pesquisa que foi feita para verificar qual linguagem gasta mais energia.
Na implementação utilizada, C foi a linguagem cujo código gerado usou menos energia; em segundo, com uma utilização apenas 3% maior, Rust.
Ainda, em tempo de execução, a aplicação gerada em C também é a mais rápida e Rust fica em segundo com um tempo de execução apenas 4% maior.
No quesito utilização de memória é que vemos algo engraçado: A linguagem que melhor utiliza memória é Pascal, C utiliza 17% mais memória e Rust 54% a mais. A explicação para isso pode ser pela forma como Rust trata memória, principalmente de código, mas eu vou explicar isso melhor mais pra frente.
E, apesar disso tudo, Rust tem implementações de:
- Strings com tamanho crescente;
- Listas dinâmicas;
- Mapas.
E considerando todo o tempo que eu passei programando em várias linguagens, se amanhã surgisse uma linguagem que conseguisse ter uma performance melhor que C, mas que eu tivesse que implementar minha própria lista encadeada, eu acredito que botaria fogo em tudo e iria plantar batatas, porque, honestamente, significa que nós não aprendemos nada sobre linguagens de programação.
Motivo 3: Compilador É Chato, Mas Amigável
Deixem-me mostrar um código Rust:
fn main() {
let a = 2;
a = 3;
println!("{}", a);
}
Aqui temos nosso primeiro contato com a sintaxe de Rust: fn define funções;
assim como C, main é a função que indica onde a execução começa; let deixa
definir variáveis e, apesar de não mostrar nesse trecho, as variáveis são
fortemente tipadas, mas eu não precisei colocar o tipo porque o compilador
consegue inferir o tipo sozinho (com algumas raras exceções); linhas terminam
com ;; println! tem uma exclamação porque essa função é uma macro e a
exclamação é colocada para diferenciar de funções normais (no caso, o
println! vai ser expandido pelo compilador por um conjunto maior de
comandos).
{% note() %}
Quem já brincou com #defines em C deve saber que não existe nada que indique
o que foi digitado é uma função mesmo ou um #define que vai ser expandido em
várias outras funções; Rust não deixa isso acontecer.
{% end %}
Outra coisa a notar é que não estamos definindo o tipo de variável que a é.
Rust é uma linguagem fortemente e estaticamente tipada. O que está acontecendo
é que estamos deixando o compilador inferir qual o tipo que a deve ter -- e
por ser um inteiro, provavelmente vai ser um u32 ou u64, dependendo da
arquitetura, pois para desambiguação, Rust usa o tipo que gere um código mais
rápido, mesmo que ocupe mais memória.
E esse código Rust não compila.
Se vocês tentarem compilar esse código, vocês verão a seguinte mensagem de erro:
3 | let a = 2;
| -
| |
| first assignment to `a`
| help: make this binding mutable: `mut a`
4 | a = 3;
| ^^^^^ cannot assign twice to immutable variable
O que acontece é que, em Rust, alem das variáveis serem fortemente tipadas, elas também são, por padrão, imutáveis. Ou seja, não é possível, por padrão, alterar o valor de uma variável.
Mas prestem atenção na mensagem de erro:
4 | a = 3;
| ^^^^^ cannot assign twice to immutable variable
O compilador não apenas disse qual era o erro -- "não é possível atribuir um valor duas vezes para uma variável imutável" (indicando, ainda qual a linha) como também passou uma dica de como corrigir esse problema:
| help: make this binding mutable: `mut a`
{% note() %} Essa parte da mensagem de erro é importante para o time de desenvolvimento do Rust.
Na Rust Latam, Esteban Kuber fez uma apresentação chamada "Friendly Ferris: Developing Kind Compiler Errors" ("Ferris Amigável: Desenvolvendo Erros Amigáveis do Compilador", onde "Ferris" é o nome do mascote da linguagem), onde ele conta que foi brincar com Rust pela primeira vez e recebeu um erro do compilador sobre o código que ele tinha escrito, mas não conseguiu entender exatamente qual era o problema.
Aqui fica a pergunta pra vocês: Se vocês encontrassem um erro que não entendessem o que vocês fariam? Boa parte provavelmente diria que iria perguntar ao Google.
Esteban, no entanto, resolveu abrir um issue no Github da linguagem, para ver o que iria acontecer. A resposta? "Você tem razão, a mensagem do erro é difícil de entender, e isso é um bug do compilador. Nós vamos arrumar." Esteban se ofereceu pra tentar encontrar o problema, recebeu uma tutoria de como compiladores funcionam e hoje é um dos expoentes nas questões de mensagens de erro do compilador. {% end %}
Motivo 4: O Borrow Checker
O Borrow Checker é a funcionalidade que faz o Rust ser diferente de outras linguagens. E que também mudou como eu pensava sobre programação, apesar de todas as linguagens listadas no começo desse post.
Por exemplo, no seguinte código:
let a = String::from("hello");
{% note() %} O que está sendo feito aqui é que está sendo criada uma string -- uma lista de caracteres que pode ser expandida, se necessário -- utilizando uma constante que é fixa (por ficar em uma página de código em memória) como valor inicial.
Quem já mexeu com C: Isso é o mesmo que alocar uma região de memória e copiar o conteúdo de uma variável estática para a nova região alocada. {% end %}
Quando vocês olham esse código, o que vocês pensam?
Eu sempre li como "A variável a recebe o valor hello".
Eu nunca pensei nisso como "A posição de memória apontada por a tem o valor
hello"; ou algo como let 0x3f5cbf89 = "hello".
Entretanto, é isso que o compilador do Rust faz: cada atribuição de variável é considerada como um indicador de uma posição de memória, algo do tipo
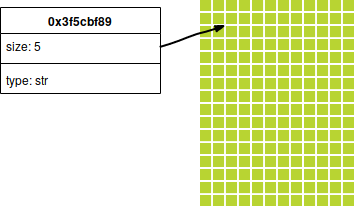
No caso, a (a nossa variável) é "dona" de uma região de memória, a
0x3f5cbf89, que tem o tamanho de 5 bytes, do tipo String.
E aí você faz uma atribuição de variáveis como, por exemplo:
fn main() {
let a = String::from("hello");
let _b = a;
println!("{}", a)
}
... tudo parece normal.
Exceto que esse código não compila.
error[E0382]: borrow of moved value: `a`
--> src/main.rs:5:20
|
4 | let _b = a;
| - value moved here
5 | println!("{}", a)
| ^ value borrowed here after move
|
= note: move occurs because `a` has type
`std::string::String`, which does not
implement the `Copy` trait
Por que? Porque a região de memória que a apontava (aquela que fica em
0x3f5cbf89, que tem 5 bytes e é do tipo String) agora pertence a b; a fica
apontando para... nada. E "nada", não é null: como todas as variáveis tem
que apontar para uma posição de memória, a se torna inválido e não pode mais
ser utilizado.
"Mas e se eu precisar acessar uma posição de memória/valor em mais de um
lugar?" Bom, aí você pode usar referências, usando &:
fn main() {
let a = String::from("hello");
let _b = &a;
println!("{}", a)
}
Utilizar referências faz, basicamente, isso:
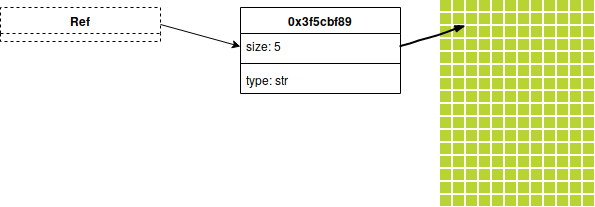
Existem várias regras que o Borrow Checker executa:
- Uma região de memória tem apenas um dono;
- Passar um valor (região de memoria) de uma variável para outra troca o dono;
- A região é desalocada quando o dono sair de escopo;
{% note() %}
Estas três regras estão interligadas: com a memória sendo desalocada quando a
variável sai de escopo, não precisamos mais nos preocupar em fazer free()
(apesar de que, agora, precisamos nos preocupar quanto tempo queremos que a
variável/região de memória permaneça alocada através dos nossos blocos de
código); tendo apenas um dono (e esse dono muda em caso de atribuição),
evita-se o problema de um "double free()".
{% end %}
- Uma região de memória pode ter infinitas referências;
- ... desde que elas não durem mais que o dono da região original;
{% note() %}
As referências não devem durar mais que a variável original para evitar que
elas continuem sendo utilizadas depois que o valor original foi feito
free().
{% end %}
- Assim como temos variáveis definidas como mutáveis, referências também podem ser criadas como mutáveis;
- Não é possível criar referências mutáveis de variáveis imutáveis;
- Para haver uma referência mutável, é preciso que ela seja a única referência (mutável ou não).
{% note() %} Isso garante que não existam duas threads tentando escrever na mesma posição de memória ao mesmo tempo. {% end %}
Ok, com todas essas regras, você deve estar se perguntando: E pra que serve tudo isso?
Duas respostas para essa pergunta:
A primeira é o seguinte código (em Go, porque é mais fácil de explicar):
presente := Presente { ... }
canal <- presente
presente é uma estrutura qualquer que eu criei; canal é o canal de
comunicação entre duas threads; o que está sendo feito aqui é que uma thread
está criando uma estrutura e enviado para o outra thread.
Nada demais; o problema está em fazer algo do tipo:
presente := Presente { ... }
canal <- presente
presente.abrir()
Se eu enviei o presente para outra pessoa, como foi que eu abri? Se eu mandei uma estrutura para outra thread, como foi que o compilador deixou eu fazer uma alteração nessa estrutura, se agora ela é da outra thread?
A outra resposta é que chegamos ao limite do silício. Alguns podem não saber disso, mas a pouco tempo havia uma ser "briga" entre donos de computadores pra ver qual tinha o mais potente, e nós fazíamos isso contando vantagem com o clock do processador: "O meu tem 3Ghz", "Ah, mas o meu tem 3Ghz e meio!" Esse tipo de discussão sumiu, por um único motivo: não temos mais como fazer o silício vibrar mais. A coisa ficou tão complexa que o que é feito agora é colocar mais CPUs dentro da CPU.
Para tirar proveito da "CPUs dentro da CPU", precisamos de threads, e se o compilador não proteger contra o uso inválido de memória entre as threads, nós ainda vamos ter aqueles alertas de que a aplicação parou de funcionar as 4 da manhã, e você vai tentar descobrir o que aconteceu e nada faz sentido.
A ideia do Borrow Checker é tão boa que mais linguagens estão utilizando: Swift 5 tem um controle chamado "Exclusitivy Enforcement" que é, basicamente, um borrow checker mais light; Ada, uma das três linguagens aceitas pela MISRA para software em que vidas humanas estão em jogo (controle de aviões, carros e equipamentos médicos, por exemplo), ganhou um borrow checker na última versão (pelo menos, "última" no momento em que esse post estava sendo escrito).
Intervalo: Anedotas
Duas anedotas sobre a minha vida de programador:
Numa época em que eu trabalhava num projeto gigantesco em C, eu estava esperando minha carona para voltar pra casa enquanto uma das desenvolvedoras estava brigando com o código. "Eu não consigo entender, " -- disse ela -- "eu estou tentando ver o tempo que uma regra de negócio leva pra executar, mas está dando que tá levando menos de 1 segundo, quando eu sei que tem uma pesquisa no banco que é demorada!"
"Como é que tu tá pegando esse tempo de execução?" -- perguntei.
"Eu faço um localtime no começo da execução e um localtime no final e vejo
a diferença."
Nesse momento, me lembrei que localtime não é thread-safe: Quando o valor é
capturado, é passada uma região de memória a ser preenchida, mas cada vez que
o localtime é chamada, a mesma região é atualizada; o que estava acontecendo
é que as outras threads, que também estavam fazendo a chamada para localtime
estavam todas apontando para a mesma região de memória e todas elas estavam
mudando na mudança de valor.
Em tempos mais recentes, estávamos trabalhando em Java e usando
SimpleDateFormatter. Em certos casos, começamos a receber alertas do tipo
"Data inválida: ''" ou "Data inválida: "R"". "Mas como? Tá aqui o JSON de
entrada e lá tem valor!"
Mais uma vez, acendeu a luzinha na minha cabeça e a primeira coisa que eu fiz foi pesquisar "SimpleDateFormatter é thread-safe?" O primeiro resultado foi um "Por que SimpleDateFormat não é thread-safe?" Trocamos pela versão mais nova (outra classe) e tudo passou a funcionar normalmente.
Aí vem a pergunta: Se usássemos Rust ao invés de C ou Java, isso resolveria nossos problemas?"
A resposta é "Sim!", porque o Rust sequer ia deixar o código compilar -- porque, em ambos os casos, temos threads compartilhando memória mutável, que, como vimos pelas regras do Borrow Checker, não é possível fazer em Rust.
Motivo 5: Tipos Algébricos
("Tipos Algébricos", no nosso caso, é só um nome bonito para parecer inteligente ao invés de dizer "Enums".)
Rust, assim como várias outras linguagens, tem enums:
enum IpAddr {
V4,
V6
}
{% note() %} Quando eu estava estuando sobre isso, eu descobri que as opções de um enum são chamadas "variantes". {% end %}
Mas além de ter enum, uma das coisas que Rust permite é que as opções do enum carreguem um valor com elas.
enum IpAddr {
V4(String),
V6(String),
}
Aqui temos um enum com duas opções, V4 e V6; cada um dessas opções carrega
uma string junto.
Mas como se usa isso?
let home = IpAddr::V4(String::from("127.0.0.1"));
É bem parecido com a forma em que definimos os valores de enumerações em outras linguagens, com a String como parâmetro.
É importante notar que não é preciso que todas as opções tenham os mesmos parâmetros, e é possível ter opções sem nenhum parâmetro ou mesmo mais de um.
E, para acessar os elementos, usamos match:
match home {
V4(address) => println!("IPv4 addr: {}", address),
V6(address) => println!("Ipv6 addr: {}", address),
}
match usa pattern matching para validar as opções. No caso, se home for
V4 com um valor dentro, o valor é extraído e o println! com a string
IPv4 é usada; se for V6, o outro println! é usado.
A parte interessante é que se amanhã surgir o IPv8, e eu adicionar V8 no meu
enum, o código vai parar de compilar. Por que? Porque o pattern matching tem
que ser exaustivo -- ou seja, tem que capturar todas as opções possíveis. Isso
é importante para coisas como, por exemplo:
enum Option<T> {
Some(T),
None
}
Esse enum é o substituto para coisas com null; lembre-se que, em Rust, todas
as variáveis devem apontar para uma região de memória e null não é um
posição de memória e, por isso, Rust não tem nulls. Assim, uma função que
poderia retornar null tem que retornar um Option e, quando é tratado o
retorno da função, é preciso tratar o valor do retorno de sucesso (Some) e
o valor com null (None); não é possível acessar o valor com o valor de
sucesso sem tetar o que acontece se não vier valor.
E isso nos leva ao próximo motivo que é...
Motivo 6: Error Control
Antes de entrar na questão de como Rust faz o tratamento de erros, deixem me mostrar alguns exemplos de tratamentos em outras linguagens:
Em Python:
try:
something()
except Exception:
pass
Em Java:
try {
something();
} catch (Exception ex) {
System.out.println(ex);
}
Ou em C:
FILE* f = fopen("someting.txt", "wb");
fprintf(f, "Done!");
fclose(f);
Qual o problema com esses três exemplos?
O problema é que em nenhum deles a situação do erro foi realmente tratada -- a
versão em C é a pior delas, pois se o fopen falhar por algum motivo, ele
retorna um null e tentar fazer um fprintf em um null gera um
Segmentation Fault.
{% note() %} Eu já fiz todos esses, na minha vida. {% end %}
Desde a base das bibliotecas do Rust, as funções retornam esse enum:
enum Result<T, E> {
Ok(T),
Err(E),
}
Como isso ajuda em alguma coisa? Bom, se tudo retorna Result, isso significa
que a única forma que eu tenho para pegar o resultado do sucesso é lidar com o
caso do erro, porque o match não vai deixar que eu simplesmente ignore isso.
No nosso caso do C, o correspondente seria:
match File::create("something.txt") {
Ok(fp) => fp.write_all(b"Hello world"),
Err(err) => println!("Failure! {}", err),
}
Ou seja, a única forma que eu tenho de pegar o fp (file pointer) pra poder
escrever no arquivo é usando um match tratando o Ok (sucesso) e Err
(erro), e eu não tenho como pegar o fp sem fazer esse tratamento todo.
A única coisa que faltou é que o write também pode falhar; então teríamos
match File::create("something.txt") {
Ok(fp) => match fp.write_all(b"Hello world") {
Ok(_) => (),
Err(err) => println!("Can't write! {}", err),
}
Err(err) => println!("Failure! {}", err),
}
... e aqui já estamos ficando verbosos demais. Para facilitar um pouco a vida,
o enum Result do Rust tem uma função chamada .unwrap(), que faz o
seguinte: se o resultado do Result for Ok, já extrai o valor e retorna o
valor em si; se o resultado for Err, chama um panic!, que faz a aplicação
"capotar":
let mut file = File::create("something.txt").unwrap();
file.write(b"Hello world").unwrap();
"Mas Júlio", você deve estar pensando, "isso não é diferente do segmentation
fault". Em matéria de resultado final, não; mas se vocês pensarem bem, o que
está sendo feito é que explicitamente eu estou colocando um "aqui a aplicação
pode explodir", e não que alguma coisa em tempo de execução vai derrubar a
aplicação. E a palavra chave aqui é "explicitamente"; alguém pode considerar
que não tratar o null do fopen também é uma forma de deixar um "aqui a
aplicação pode explodir", mas não foi o compilador que deixou isso acontecer;
sempre que pode, o compilador do Rust tentou me impedir de fazer burrada.
Outra forma de lidar com Result é o operador ?: o que ela faz é que
caso a chamada de função retorne um Err, esse Err é passado como retorno
da função com o operador; se a função retornar um Ok, então o valor
encapsulado é retornado diretamente. Mais uma vez no nosso exemplo da escrita
em arquivo:
let mut file = File::create("something.txt")?;
file.write(b"Hello world")?;
OK(())
Como o operador vai fazer com que a função em que essas linhas estão retornem
o Err se a chamada falhar, essas três linhas tem que estar dentro uma
função que retorne um Result.
"Ah, barbada", você pensa, "vou botar ? em tudo e nunca lidar com o erro".
Bom, sim, é uma opção, mas existe uma função que não se pode ter Result: a
main. Assim, mais cedo ou mais tarde, o erro vai ter que ser lidado.
{% note() %}
Existe uma forma de fazer o main retornar Result, mas ele basicamente
serve para transformar o Result num código de erro -- ou 0 em sucesso.
{% end %}
Motivo 7: Generics & Traits
Antes de entrar direto sobre generics e traits, vamos falar sobre qual estrutura Rust usa para guardar os dados.
Rust usa structs, como C, e não classes como C++ e mais uma gama de outras linguagens.
Por exemplo:
struct Gift {
package_color: String,
content: String
}
Lembram que eu no começo comentei que Rust era fortemente e estaticamente tipada e que o compilador estava inferindo o tipo dos dados para nós? Bom, para estruturas isso não funciona, e por isso precisamos definir os tipos aqui.
Para criar um elemento dessa estrutura, usamos
let presente = Gift { package_color: "red", content: "A GIFT!" };
{% note() %} Eu normalmente não comento isso nas apresentações que eu faço, mas é possível criar uma estrutura do tipo
struct Gift(String);
Essa estrutura tem os campos com nomes anônimos e temos que acessar com .0
ou .1 (se tiver um segundo campo nessa estrutura) e assim por diante.
Esse tipo de construção normalmente é usada para forçar novos tipos no sistema, já que se eu quisesse receber um tipo específico de String, eu usaria algo do tipo.
Outro exemplo, que talvez fique mais claro:
struct Celcius(f32);
struct Farenheit(f32);
Duas estruturas -- dois tipos -- que englobam floats, mas quando eu estiver
lendo o código e ver uma função do tipo convert(c: Celcius), eu sei
exatamente qual a unidade de temperatura que eu preciso passar, deixando o
código mais claro de ser lido.
{% end %}
Generics -- a possibilidade de não definir o tipo de um dado previamente é
feito como em Java, onde os tipos genéricos são listados entre <>:
struct Point<T> {
x: T,
y: T,
}
Se eu quiser criar um Point com floats de 32 bits:
let my_point = Point<f32>(x: 1.0, y: 2.0);
Além de aplicar Generics para estruturas, podemos aplicar o mesmo para enums -- e nós já vimos dois exemplos disso:
enum Option<T> {
Some(T),
None
}
Option, o substituto de coisas que podem ser null/não ter valor é uma
enumeração com Some que carrega um tipo qualquer, definido quando se cria
uma variável com essa variante -- e é possível deixar o compilador inferir
qual o tipo, assim como fizemos com a nos primeiros exemplos:
let has_value = Some(2);
Outro exemplo básico de enum genérico:
enum Result<T, E> {
Ok(T),
Err(E),
}
Result também permite que sejam carregados valores com as variantes; no
caso, tanto o tipo do Ok quanto Err são genéricos e possivelmente
diferentes -- Ok pode ter um tipo T, enquanto Err tem um tipo qualquer
E, e não há nada obrigando os dois a terem o mesmo tipo, como seria se
tivéssemos:
enum Result<T> {
Ok(T),
Err(T)
}
... onde tanto o tipo do sucesso quanto de erro devem ser do mesmo tipo.
{% note() %}
Em tempo de compilação, Rust vai resolver todos os tipos que as
estruturas, enums e funções genéricas usam e vai gerar o código para esses
tipos -- ou seja, se eu tivesse duas funções que retornam Result, uma com
Result<u32, String> e Result<f32, String>, em tempo de compilação seriam
geradas duas versões diferentes de Result, com os tipos já definidos.
A vantagem disso é que, em tempo de execução, não é preciso tentar detectar o tipo que está sendo passado, já que ele já foi definido muito antes. O problema é que o código pode ficar maior -- e isso deve explicar o tamanho dos executáveis como foi mostrado lá no começo do post. {% end %}
Além de estruturas de dados, é possível adicionar funções atreladas à essas estruturas:
impl Gift {
fn yell_content(&self) {
println!("{}", self.content);
}
}
(Com exceção de hierarquias, o resultado é bem semelhante à programação orientada e objetos.)
Ainda é possível definir interfaces que várias estruturas devem implementar, utilizando-se traits:
trait Summary {
fn summarize(&self) -> String;
}
Essa trait indica que, qualquer estrutura que queira ser compatível com ela,
tem que implementar uma função summarize que retorna uma String.
Para definir que uma estrutura segue a trait, utiliza-se impl/for:
struct Phrase {
phrase: String
}
impl Summary for Phrase {
fn summarize(&self) -> String {
self.phrase
.split_whitespace()
.map(|word| word.chars().nth(0).unwrap())
.collect()
}
}
{% note() %} Se você está com curiosidade com relação ao código acima:
- Pega o
phrase, que foi definido na estrutura comoString; - Quebra essa string pelos espaços em branco (
split_whitespace), gerando uma lista; - Transforma (
map) cada elemento da lista (que chamamos dewordnesse caso) para pegar o primeiro elemento da lista de caracteres que forma a string (chars().nth(0).unwrap()). Ounwrapestá aqui porquenthretorna umOption, já que pode ser chamado com um número maior que caracteres na String, retornandoNonenesse caso; ounwrapserve para pegarmos diretamente o valor doSomee, por sorte, não vai haver nenhum pedaço da string quebrada comsplit_whitespaceque não tenha nenhum caractere; - Junta (
collect) todos os elementos. Como Strings são arrays/listas de caracteres, há uma conversão direta para String.
Ou seja, a função pega uma string como "Porque Você Deve Aprender Rust" e retorna "PVDAR". {% end %}
Traits funcionam com Generics, e assim podemos forçar a receber estruturas/enums que tenham certas características, como em:
fn get_summary<T>(summarizable: T) -> String
where T: Summary
{
...
}
Aqui temos uma função genérica que recebe um tipo qualquer T, mas obrigamos,
através do where que esse tipo implemente a trait Summary -- e assim
podemos chamar summarizable.summarize() sem problemas, porque a trait obriga
o tipo a ter essa função implementada.
Outra vantagem desse formato é que podemos ter traits próprias do nosso sistema, mas implementar a trait para tipos já definidos na linguagem:
impl Summary for String { ... }
Motivo 8: Cargo
Cargo é o gerenciador de pacotes e dependências do Rust. Ele também serve como gerenciador de projetos e frontend para outras funcionalidades, como executar testes.
Cargo é interessante porque faz parte do pacote principal do Rust -- em outras palavras, a linguagem já vem com um eco-sistema completo.
Motivo 9: Testes
Rust já vem com testes integrados -- e, como comentado no motivo anterior, Cargo serve como facilitador para a execução dos testes.
Por exemplo, o seguinte código mostra um teste em Rust:
#[cfg(test)]
mod tests {
#[test]
fn testing() {
assert!(1 == 1);
}
}
Esse teste não precisa estar num arquivo específico (mas ajuda se você coloca
num arquivo específico); ele não precisa estar em um módulo específico (ou
seja, aquele mod tests não necessariamente precisa existir ou mesmo se
chamar tests); e as funções não precisam começar com um nome específico.
Tudo que você precisa é definir que o código somente vai existir na
configuração de testes (#[cfg(test)]) e marcar cada função que deve ser
chamada durante os testes (#[test]).
Para ver os resultados do teste:
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished dev [unoptimized + debuginfo] target(s) in 0.22 secs
Running target/debug/deps/adder-ce99bcc2479f4607
running 1 test
test tests::testing ... ok
Ao executar cargo test, todos os arquivos marcados com testes são compilados
(porque o cargo já ativou a configuração de testes e os blocos marcados são
finalmente adicionados) e executa os testes, mostrando o resultado de cada um.
Não é preciso uma biblioteca externa ou comandos a mais para escrever um
teste.
{% note() %}
Uma coisa curiosa sobre o cargo test é que ele também sai executando tudo
que estiver no diretório examples, que normalmente contém exemplos de como
uma biblioteca funciona.
A parte interessante sobre isso é que durante a execução de testes de várias bibliotecas, também é validado se os exemplos estão corretos. {% end %}
Motivo 10: Macros
Macros são uma ferramenta poderosa mas realmente complexa do Rust. Tão complexa que eu não cheguei a me aprofundar muito, mas como exemplo, deixem-me mostrar uma biblioteca do Rust, chamada Log-Derive:
#[logfn(ok = "TRACE", err = "ERROR")]
fn call_isan(num: &str) -> Result<Success, Error> {
if num.len() >= 10 && num.len() <= 15 {
Ok(Success)
} else {
Err(Error)
}
}
A parte da macro está no começo da função, no #[logfn(ok = "TRACE", err = "ERROR")]; o que ela indica é que se a função terminar com o status de Ok,
deve ser gerado um log no nível "TRACE" (abaixo de "DEBUG") e se a função sair
com status de Err, deve ser gerado um log no nível de "ERROR".
E aí eu pergunto: Você consegue ver alguma linha de log no código da função? Isso é porque a macro do Log-Derive consegue acessar o código em tempo de compilação e adicionar/alterar certas construções.
{% note() %} Na verdade, eu sei que existem três tipos diferentes de macros em Rust:
- Macros mais simples, como a
println!, que se expandem para uma combinação maior de comandos (println!expande para a aquisição do lock da escrita padrão -- stdout -- envio dos dados para a saída e liberação do lock, mas você nunca teve que escrever tudo isso por conta); - Macros de implementação de funções em estruturas, que basicamente fazem a
geração de funções como vimos com
impl; - E macros como a Log-Derive, que tem acesso aos tokens que formam o código fonte e geram uma saída de tokens novamente -- e aí podem adicionar, remover ou alterar tokens do jeito que quiserem. {% end %}
Motivo 11: Motivos Malucos
How Rust’s standard library was vulnerable for years and nobody noticed: Nesse artigo de 2018, Sergey Davidoff conta que achou uma falha de segurança em uma das funções do Rust, mas devido a forma como a mesma deveria ser chamada, era basicamente impossível de exploitar a mesma.
No, the problem isn’t “bad coders”: Esse artigo é uma resposta para as respostas de um artigo da Microsoft, em que eles reportam que 70% de todos os crashes das aplicações no Windows se devem ao acesso inválido de memória. Sean Griffin, criador da biblioteca Diesel, que serve para escrever ORMs em Rust, conta que estava trabalhando em compartilhar uma conexão do PostgreSQL entre várias threads, e o compilador não deixou. Quando foi examinar exatamente o porque, percebeu que realmente o que ele queria fazer poderia levar a um acesso inválido. E Griffin tem experiência de sobra nesse campo, já que também é o criador do Active Record do Rails.
Outra coisa maluca:

A parte que vocês devem estar estranhando é a quantidade de issues que a linguagem tem (algumas vezes o Github chega simplesmente a mostrar "5000+", indicado que existem mais de 5000 issues abertas).
Como pode uma linguagem com apenas 4 anos de existência pública ter mais de 5000 issues abertas? O que acontece é que todo o processo de decisão da linguagem passa pelo Github: Quando os desenvolvedores do core da linguagem acreditam que uma funcionalidade deva ser adicionada (ou removida), o que eles fazem é abrir uma issue no Github para discutir com a comunidade o que e como isso deve ser feito.
Lembram que eu comentei que as questões de mensagens de erro não claras podem (e devem) ser comunicadas para os desenvolvedores? Isso é feito pelo Github.
Ainda, existem "Working Groups", grupos especializados sobre discussões em alguns tópicos. Por exemplo, existe um working group para Bancos de Dados, discutindo como a linguagem pode facilitar a criação de conexões com vários bancos, interfaces padrões para essas conexões e assim por diante; existe um working group para jogos, para discutir as coisas que tornam a vida de desenvolvedores de jogos mais fácil.
{% note() %} Existia um working group para CLI (command line interface, ou interface de linha de comando) para discutir como facilitar a vida de desenvolvedores que querem construir ferramentas de linhas de comando. Uma vez que o grupo acreditou ter achado a melhor forma, eles publicaram um livro sobre os achados, decisões e implementações.
E isso acontece com todos os working groups -- então pode esperar que, se eles não fizeram ainda, vai sair um livro de como utilizar bancos de dados com Rust do Database Working Group e um livro de como escrever jogos em Rust pelo Games Working Group. {% end %}
Por último, existe o script rustup. Lembram que eu falei
que Rust tem uma cadência de releases de seis em seis semanas? RustUp ajuda a
manter a sua instalação do Rust -- e componentes associados -- em dia. Não só
isso, mas ele permite a instalação de "toolchains" diferentes: Você pode, por
exemplo, instalar o toolchain para a arquitetura
armv7-unknown-linux-gnueabihf e, a partir da sua máquina Linux rodando Intel
gerar um executável para arquitetura ARM; ou, ainda, você pode instalar o
toolchain para a arquitetura wasm32-unknown-unknown que, na verdade, não é
uma arquitetura, é o gerador para WebAssembly, o que permite que você converta
seu código Rust para WebAssembly (com algumas restrições) -- e, embora seja
possível gerar WebAssembly em outras linguagens como C++ e C#, se você
utilizar Rust, todas as validações de acesso de memória continuam valendo.
E agora?
Bom, se depois de tudo isso você decidir que quer aprender mais sobre Rust, o que eu posso sugerir é:
- Instale o Rust usando o RustUp.
- Leia o Livro do Rust; o livro que explica todas as funcionalidades da linguagem está disponível online e é possível comprar a versão em ePub da No Starch Press (mas não há diferença entre a versão online e a impressa/ePub).
- Confira como Rust funciona lendo o Rust By Example. Basicamente tudo que o Livro cobre também está aqui, mas Rust By Example usa uma forma diferente de explicação, partindo a partir de exemplos para cada ponto.
- Você pode brincar com Rust no Rust Playground, onde é possível editar, compilar e executar código Rust de dentro do browser. Somente um número pequeno de bibliotecas está disponível, mas para brincar com Rust básico é possível usar isso ao invés de instalar a linguagem inteira.
- Existe um grupo de usuários de Rust no Telegram, o Rust Brasil. Se tiver alguma dúvida, é só ir lá e perguntar.
E era isso!